
Dmitry Shurov
Verified Expert in 工程
Dmitry是一名软件开发人员和Python专家. 他在卡巴斯基(卡巴斯基)和FABLEfx等公司有8年的工作经验, 并在全球使用Kafka和Python开发了多个微服务系统.
Previously At

Dmitry是一名软件开发人员和Python专家. 他在卡巴斯基(卡巴斯基)和FABLEfx等公司有8年的工作经验, 并在全球使用Kafka和Python开发了多个微服务系统.
对于许多关键的应用程序功能, 包括流媒体和电子商务, 单片架构已经不够了. 满足当前对实时事件数据和云服务使用的需求, many modern applications, such as Netflix 和 Lyft, have shifted to an event-driven microservices 方法. 分离的微服务可以相互独立地运行,并增强代码库的适应性和可伸缩性.
但是什么是事件驱动的微服务架构,为什么要使用它? 我们将检查基本方面,并为事件驱动的微服务项目创建一个完整的蓝图 Python 和 Apache卡夫卡.
事件驱动的微服务结合了两种现代架构模式:微服务架构和事件驱动的架构. 尽管微服务可以与请求驱动的REST架构配对, 随着大数据和云平台环境的兴起,事件驱动架构正变得越来越重要.
微服务架构是一种软件开发技术,它将应用程序的流程组织为松耦合的服务. It is a type of 面向服务的体系结构.
在传统的整体结构中, all application processes are inherently interconnected; if one part fails, the system goes down. 相反,微服务架构将应用程序流程分组为与轻量级协议交互的独立服务, 提供改进的模块化和更好的应用程序可维护性和弹性.

虽然单片应用程序可能更容易开发、调试, 测试, 和部署, 大多数企业级应用程序都将微服务作为其标准, 哪一个允许开发人员独立拥有组件. 成功的微服务应该尽可能保持简单,并使用生成并发送到事件流或从事件流中消费的消息(事件)进行通信. JSON、Apache Avro和Google Protocol Buffers是数据序列化的常用选择.
事件驱动的体系结构是一种设计模式,它构建软件,使事件驱动应用程序的行为. 生成的有意义的数据 演员 (i.e.、人类用户、外部应用程序或其他服务).
Our example project features this architecture; at its core is an event-streaming platform that manages communication in two ways:
In more technical terms, 我们的事件流平台是充当服务之间的通信层并允许它们交换消息的软件. 它可以实现各种消息传递模式,例如 publish/subscribe or point-to-point messaging, as well as message queues.

使用带有事件流平台和微服务的事件驱动架构提供了大量的好处:
使用事件驱动的体系结构,很容易创建对任何系统事件作出反应的服务. 您还可以创建包含一些手动操作的半自动管道. (For example, 用于自动用户支付的管道可能包括在转移资金之前由异常大的支付值触发的手动安全检查.)
我们将使用Python和Apache卡夫卡以及Confluent Cloud来创建我们的项目. Python is a robust, reliable st和ard for many types of software projects; it boasts a large 社区 和 plentiful libraries. 它是创建微服务的好选择,因为它的框架适合REST和事件驱动的应用程序.g.弗拉斯克和 Django). 用Python编写的微服务也经常用于Apache卡夫卡.
Apache卡夫卡是一个著名的事件流平台,它使用发布/订阅消息模式. 由于其广泛的生态系统,它是事件驱动架构的常见选择, 可伸缩性(其容错能力的结果), storage system, 和 stream processing abilities.
最后, 我们将使用Confluent作为我们的云平台来有效地管理Kafka,并提供开箱即用的基础设施. 如果您正在使用AWS基础设施,AWS MSK是另一个很好的选择, 但Confluent更容易设置,因为Kafka是其系统的核心部分,它提供了一个免费的层.
我们将在Confluent Cloud中设置Kafka微服务示例, create a simple message 生产商, 然后对其进行组织和改进,以优化可扩展性. By the end of this tutorial, 我们将拥有一个功能正常的消息生成器,它可以成功地将数据发送到我们的云集群.
我们将首先创建一个Kafka集群. Kafka集群承载Kafka服务器,促进通信. 生产者和消费者使用Kafka主题(存储记录的类别)与服务器交互.
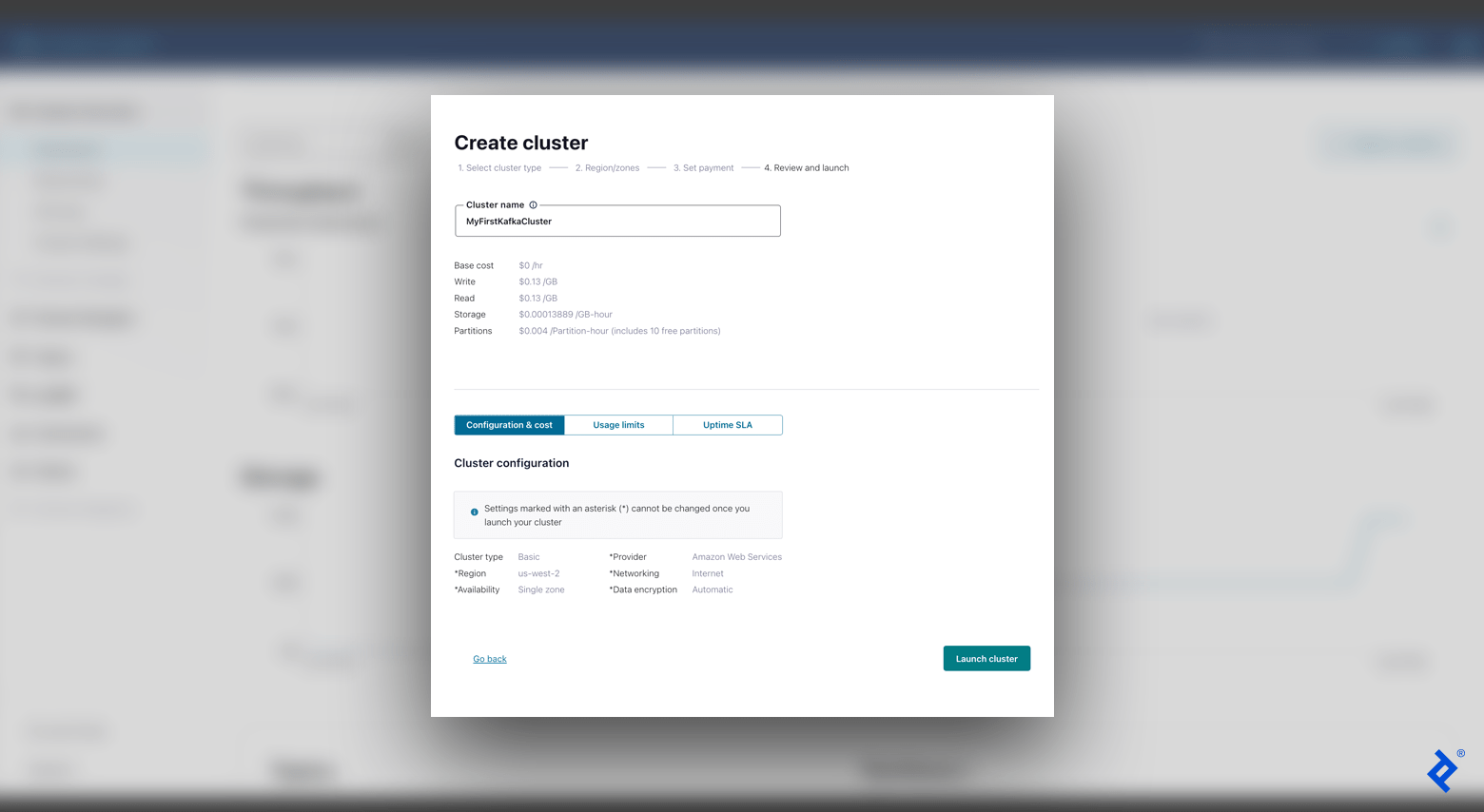
有了一个工作集群,我们就可以创建第一个主题了. 在左侧菜单栏中,导航到 主题 并点击 Create topic. 添加一个 topic name (e.g., “MyFirstKafkaTopic”)并继续默认配置(包括设置六个分区).
在创建第一条消息之前,我们必须设置客户端. We can easily Configure a client 从我们新创建的主题概述(或者,在左侧菜单栏中)导航到 客户). 我们将使用 Python as our language 和 then click Create Kafka cluster API key.

至此,我们的事件流平台终于准备好接收来自生成器的消息了.
我们的生产者生成事件并将它们发送给Kafka. 让我们编写一些代码来创建一个简单的消息生成器. 我建议 设置虚拟环境 对于我们的项目,因为我们将在我们的环境中安装多个包.
首先,我们将从Confluent Cloud的API配置中添加环境变量. 要在虚拟环境中执行此操作,我们将添加 export SETTING=value 对于下面的每个设置到我们的结束 激活 文件(或者,您可以添加 SETTING=value 到你的 .env文件):
export KAFKA_BOOTSTRAP_SERVERS=
export KAFKA_SECURITY_PROTOCOL=
export KAFKA_SASL_MECHANISMS=
export KAFKA_SASL_USERNAME=
export KAFKA_SASL_PASSWORD=
确保将每个条目替换为Confluent Cloud值(例如, 平原),以您的API密钥和秘密作为用户名和密码. 运行 source env/bin/激活,然后 printenv. 我们的新设置应该出现,确认我们的变量已经正确更新.
我们将使用两个Python包:
python-dotenv 包:加载和设置环境变量.confluent-kafka 包: Provides 生产商 和 consumer functionality; our Python client for Kafka.We’ll run the comm和 PIP安装confluence -kafka python-dotenv to install these. There are many other 包s for Kafka 在扩展项目时可能会很有用.
最后,我们将使用Kafka设置创建基本的生产者. 添加一个 simple_生产商.py 文件:
# simple_生产商.py
进口操作系统
从confluent_kafka导入KafkaException
from dotenv import load_dotenv
def main ():
settings = {
的引导.servers': os.采用“KAFKA_BOOTSTRAP_SERVERS”),
的安全.protocol': os.采用“KAFKA_SECURITY_PROTOCOL”),
“sasl.mechanisms': os.采用“KAFKA_SASL_MECHANISMS”),
“sasl.username': os.getenv('KAFKA_SASL_USERNAME'),
“sasl.password': os.getenv('KAFKA_SASL_PASSWORD'),
}
生产商 = Producer(settings)
生产商.生产(
topic='MyFirstKafkaTopic',
关键=没有
value='MyFirstValue-111',
)
生产商.冲洗() #等待收到消息的确认
if __name__ == '__main__':
load_dotenv()
main ()
使用这段简单的代码,我们创建了生成器并向它发送了一条简单的测试消息. To 测试 the result, run python3 simple_生产商.py:

Checking our Kafka cluster’s Cluster Overview > Dashboard,我们将在产品ion图上看到发送消息的新数据点.
Our 生产商 is up 和 running. 让我们重新组织我们的代码,使我们的项目更加模块化和 OOP-friendly. 这将使将来添加服务和扩展项目变得更加容易. 我们将代码分成四个文件:
kafka_settings.py保存我们的Kafka配置.kafka_生产商.py: Contains a custom 生产() method 和 error h和ling.kafka_生产商_message.py:处理不同的输入数据类型.advanced_生产商.py:使用自定义类运行我们的最终应用程序.首先,我们 KafkaSettings 类将封装我们的Apache卡夫卡设置, 因此,我们可以轻松地从其他文件访问这些文件,而无需重复代码:
# kafka_settings.py
进口操作系统
class KafkaSettings:
def __init__(自我):
自我.Conf = {
的引导.servers': os.采用“KAFKA_BOOTSTRAP_SERVERS”),
的安全.protocol': os.采用“KAFKA_SECURITY_PROTOCOL”),
“sasl.mechanisms': os.采用“KAFKA_SASL_MECHANISMS”),
“sasl.username': os.getenv('KAFKA_SASL_USERNAME'),
“sasl.password': os.getenv('KAFKA_SASL_PASSWORD'),
}
接下来,我们 KafkaProducer allows us to customize our 生产() 方法,支持各种错误(例如.g.(消息大小太大时出现错误),也可以自动执行 flushes messages once produced:
# kafka_生产商.py
从confluent_kafka导入KafkaError, KafkaException, Producer
从kafka_生产商_message导入ProducerMessage
从kafka_settings导入kafkassettings
class KafkaProducer:
def __init__(自我, settings: kafkassettings):
自我._生产商 = Producer(settings.配置)
def 生产(自我, message: ProducerMessage):
试一试:
自我._生产商.生产(message.topic, key=message.key, value=message.值)
自我._生产商.冲洗()
except KafkaException as exc:
如果exc.args [0].code() == KafkaError.MSG_SIZE_TOO_LARGE:
pass # H和le the error here
其他:
提高exc
在我们示例的try-except块中, 如果消息太大,Kafka集群无法使用,我们就跳过它. 但是,您应该在生产环境中更新代码以适当地处理此错误. Refer to the confluent-kafka documentation 获取错误代码的完整列表.
现在,我们的 ProducerMessage 类处理不同类型的输入数据并正确序列化它们. 我们将为字典、Unicode字符串和字节字符串添加功能:
# kafka_生产商_message.py
进口json
class ProducerMessage:
def __init__(自我, topic: str, value, key=None) -> None:
自我.topic = f'{topic}'
自我.关键=关键
自我.value = 自我.convert_value_to_bytes(值)
@classmethod
Def convert_value_to_bytes(cls, 值):
if isinstance(value, dict):
返回cls.from_json(值)
if isinstance(value, str):
返回cls.from_string(值)
if isinstance(value, bytes):
返回cls.from_bytes(值)
抛出ValueError(f'错误的消息值类型:{type(值)}')
@classmethod
def from_json(cls, 值):
返回json.dump (value, indent=None, sort_keys=True, default=str, ensure_ascii=False)
@classmethod
def from_string(cls, 值):
return value.encode('utf-8')
@classmethod
def from_bytes(cls, 值):
return value
最后,我们可以使用新创建的类来构建应用程序 advanced_生产商.py:
# advanced_生产商.py
from dotenv import load_dotenv
从kafka_生产商导入KafkaProducer
从kafka_生产商_message导入ProducerMessage
从kafka_settings导入kafkassettings
def main ():
settings = KafkaSettings()
生产商 = KafkaProducer(设置)
message = ProducerMessage(
topic='MyFirstKafkaTopic',
值={“价值”:“MyFirstKafkaValue”},
关键=没有
)
生产商.生产(message)
if __name__ == '__main__':
load_dotenv()
main ()
我们现在有了一个简洁的抽象 confluent-kafka 图书馆. Our custom 生产商 具有与我们的简单生产者相同的功能,增加了可扩展性和灵活性, ready to adapt to various needs. 如果我们愿意,我们甚至可以完全改变底层库, 是什么为我们的项目的成功和长期可维护性奠定了基础.

After running python3 advanced_生产商.py,我们再次看到数据已经发送到我们的集群 Cluster Overview > Dashboard panel of Confluent Cloud. 通过简单生产者发送了一条消息, 还有我们的定制制作人, 我们现在看到了生产吞吐量的两个峰值和使用的总体存储的增加.
事件驱动的微服务架构将增强您的项目并提高其可伸缩性, 灵活性, 可靠性, 和 asynchronous communications. 本教程为您提供了这些实际好处的一瞥. 随着我们的企业规模的生产开始运转, 成功地向Kafka代理发送消息, 接下来的步骤是创建一个消费者来读取来自其他服务的这些消息,并将Docker添加到我们的应用程序中.
Toptal工程博客的编辑团队向 E. Deniz Toktay 查看本文中提供的代码示例和其他技术内容.
微服务体系结构是一种面向服务的体系结构,它将应用程序的流程组织为松耦合的服务, 与支持固有连接进程的整体结构相反.
由于其广泛的生态系统,Kafka是微服务架构的强大选择, 可伸缩性(容错能力), storage system, 和 stream processing features. 它是最受欢迎的事件流媒体平台之一.
是的,你可以在Kafka中使用Python. 将Apache卡夫卡与Python编写的微服务配对是很常见的.
事件驱动微服务结合了事件驱动架构和微服务架构. 事件驱动的体系结构是一种设计模式,它构建软件,以便事件, or meaningful data, drive an app’s behavior. 事件驱动的微服务将这种模式用于模块化的应用程序服务.
Dmitry是一名软件开发人员和Python专家. 他在卡巴斯基(卡巴斯基)和FABLEfx等公司有8年的工作经验, 并在全球使用Kafka和Python开发了多个微服务系统.
 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.世界级的文章,每周发一次.
世界级的文章,每周发一次.
Join the Toptal® 社区.
