
胡安·曼纽尔·奥尔蒂斯·德·萨拉特
Verified Expert in Engineering
Juan(计算机科学硕士)是一名数据科学/人工智能博士生. 作为一名高级web开发人员,他的主要专长包括R、Python和PHP.
Previously At
Juan(计算机科学硕士)是一名数据科学/人工智能博士生. 作为一名高级web开发人员,他的主要专长包括R、Python和PHP.
电影观众有时会用排名来选择看什么. Once doing this myself, 我注意到,许多排名靠前的电影都属于同一类型:剧情片. 这让我觉得这个排名可能存在某种类型偏见.
我在一个最受电影爱好者欢迎的网站上, IMDb, 哪个涵盖了世界各地和任何年份的电影. 其著名的排名是基于大量的评论. 对于这个IMDb数据分析, 我决定下载所有可用的信息来分析它,并尝试创建一个新的, 将考虑更广泛的标准的改进排名.
我能够下载1970年至2019年(含2019年)上映的242528部电影的信息. IMDb给我的每一个信息是: Rank, Title, ID, Year, Certificate, Rating, Votes, Metascore, Synopsis, Runtime, Genre, Gross, and SearchYear.
有足够的信息来分析, 我需要每部电影的最低评论数, 所以我做的第一件事就是过滤那些评论少于500的电影. 这导致了一组33,296 movies, and in the next table, 我们可以看到对其字段的总结分析:
| Field | Type | Null Count | Mean | Median |
|---|---|---|---|---|
| Rank | Factor | 0 | ||
| Title | Factor | 0 | ||
| ID | Factor | 0 | ||
| Year | Int | 0 | 2003 | 2006 |
| Certificate | Factor | 17587 | ||
| Rating | Int | 0 | 6.1 | 6.3 |
| Votes | Int | 0 | 21040 | 2017 |
| Metascore | Int | 22350 | 55.3 | 56 |
| Synopsis | Factor | 0 | ||
| Runtime | Int | 132 | 104.9 | 100 |
| Genre | Factor | 0 | ||
| Gross | Factor | 21415 | ||
| SearchYear | Int | 0 | 2003 | 2006 |
Note: In R, Factor refers to strings. Rank and Gross 在原始IMDb数据集中,由于有,例如,数千个分隔符,这种方式.
在开始细化分数之前,我必须进一步分析这个数据集. 首先是田地 Certificate, Metascore, and Gross 有超过50%的空值,所以它们是无用的. 排名本质上取决于评级(要改进的变量), therefore, 它没有任何有用的信息. The same is true with ID 因为它是每个电影的唯一标识符.
Finally, Title and Synopsis are short text fields. 可以通过一些NLP技巧来使用它们, 而是因为文本数量有限, 我决定在这次任务中不把它们考虑在内.
经过第一次筛选,我得到 Genre, Rating, Year, Votes, SearchYear, and Runtime. In the Genre Field,每部电影不止一种类型,用逗号分隔. 所以为了捕捉多种类型的叠加效果,我使用 one-hot encoding. 这将产生22个新的布尔字段——每个字段对应一个类型——如果电影是这种类型,则值为1,否则为0.
为了了解变量之间的相关性,我计算了 correlation matrix.
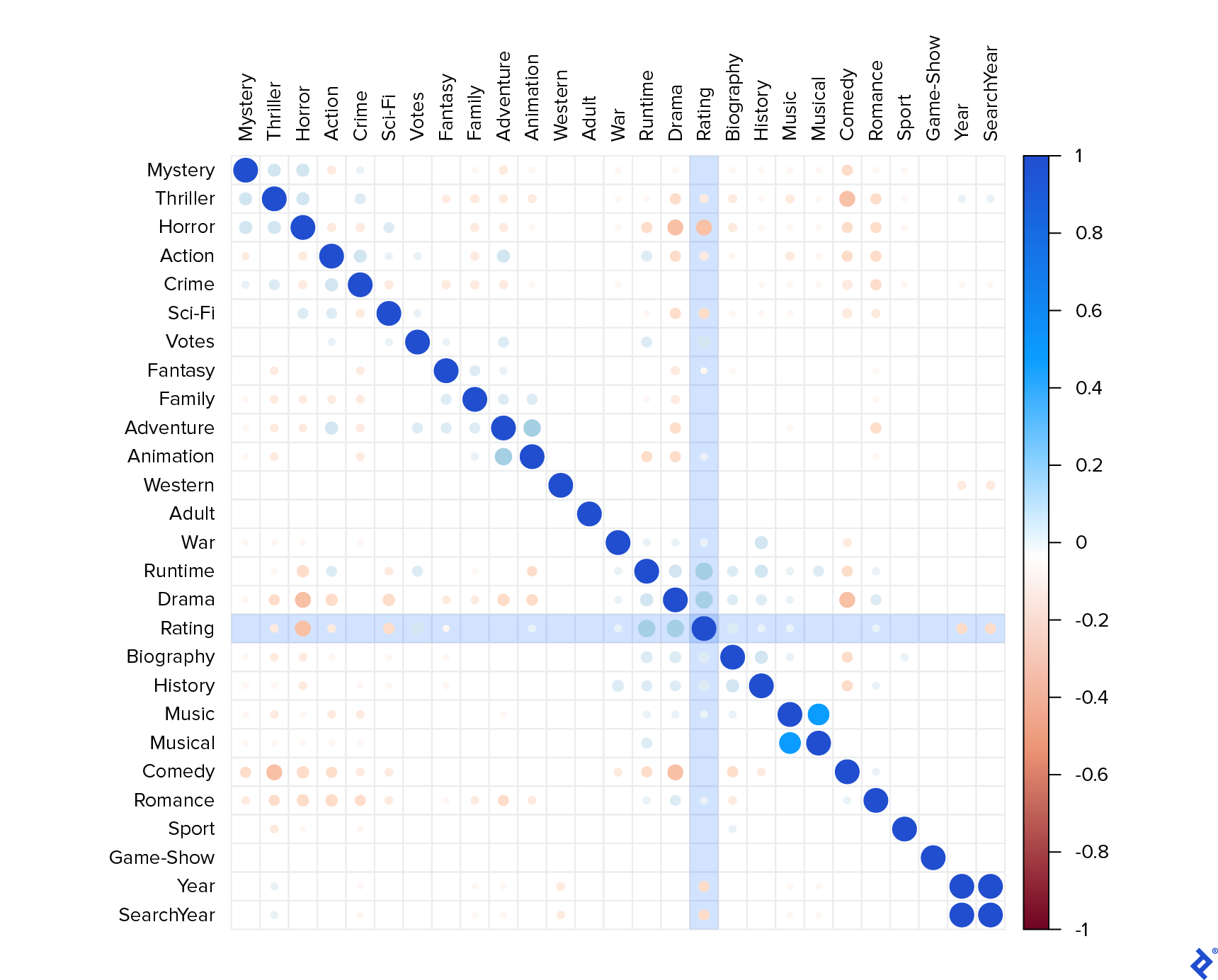
Here, 接近1的值表示强烈的正相关, 接近-1的值表示强烈的负相关. 通过这张图表,我做了很多观察:
Year and SearchYear 是绝对相关的. 这意味着它们可能具有相同的值,同时具有两个值与仅具有一个值是相同的, so I kept only Year.Music with Musical
Action with Adventure
Animation with Adventure
Drama vs. Horror
Comedy vs. Horror
Horror vs. Romance
Rating) I noticed:
Runtime and Drama.Votes, Biography, and History.Horror 还有一个低一点的负的 Thriller, Action, Sci-Fi, and Year.似乎长剧情片的收视率很高,而短恐怖片的收视率却不高. 在我看来——我没有数据来验证这一点——这与产生更多利润的电影类型无关, 比如漫威或皮克斯的电影.
这可能是因为在这个网站上投票的人并不能最好地代表一般人的标准. 这是有道理的,因为那些花时间在网站上提交评论的人可能是一些有更具体标准的电影评论家. Anyway, 我的目标是消除普通电影特征的影响, 所以我试图在这个过程中消除这种偏见.
下一步是分析每个类型在评分中的分布. 为此,我创建了一个名为 Principal_Genre 根据原著中出现的第一种体裁改编 Genre field. 为了形象化,我做了一个 violin graph.
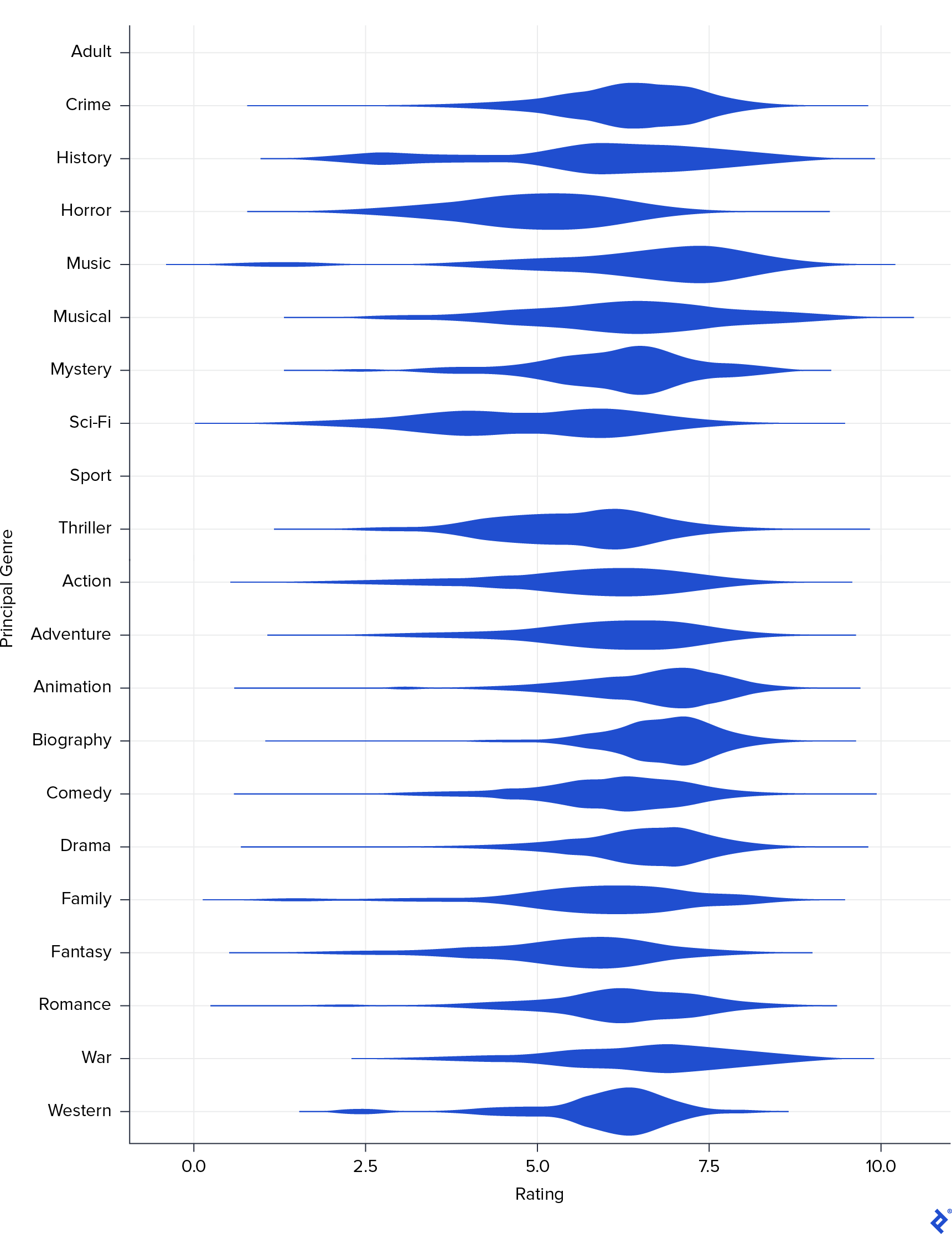
再来一次,我能看出来 Drama 与高收视率和 Horror with lower. 然而,这张图表也显示了其他类型的游戏也获得了不错的分数: Biography and Animation. 他们的相关性在之前的矩阵中没有出现,可能是因为这些类型的电影太少了. 接下来我按类型制作了一个频率条形图.
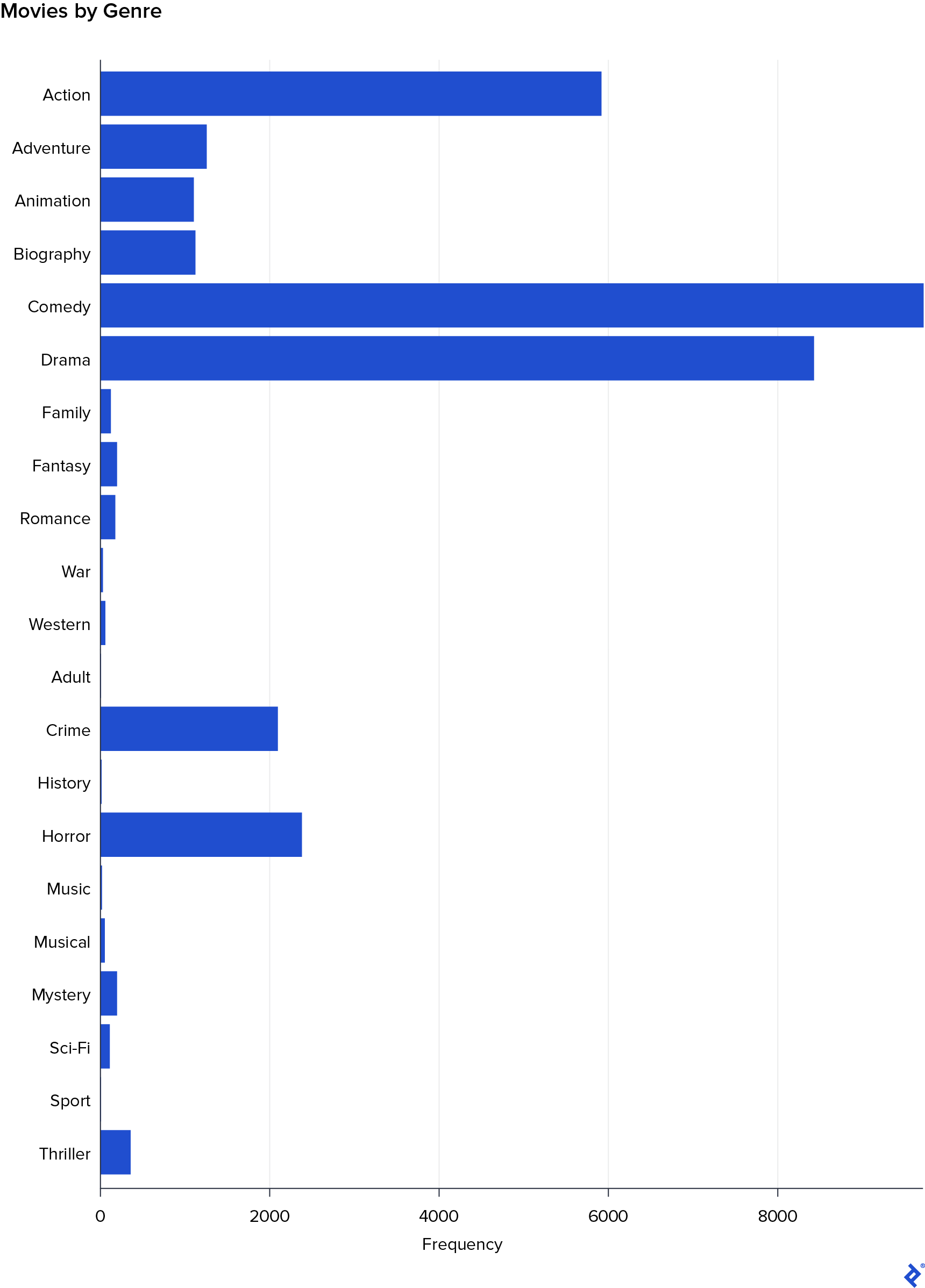
Effectively, Biography and Animation 很少有电影,是吗 Sport and Adult. 由于这个原因,它们的相关性不是很好 Rating.
之后,我开始分析连续协变量: Year, Votes, and Runtime. 在散点图中,你可以看到 Rating and Year.
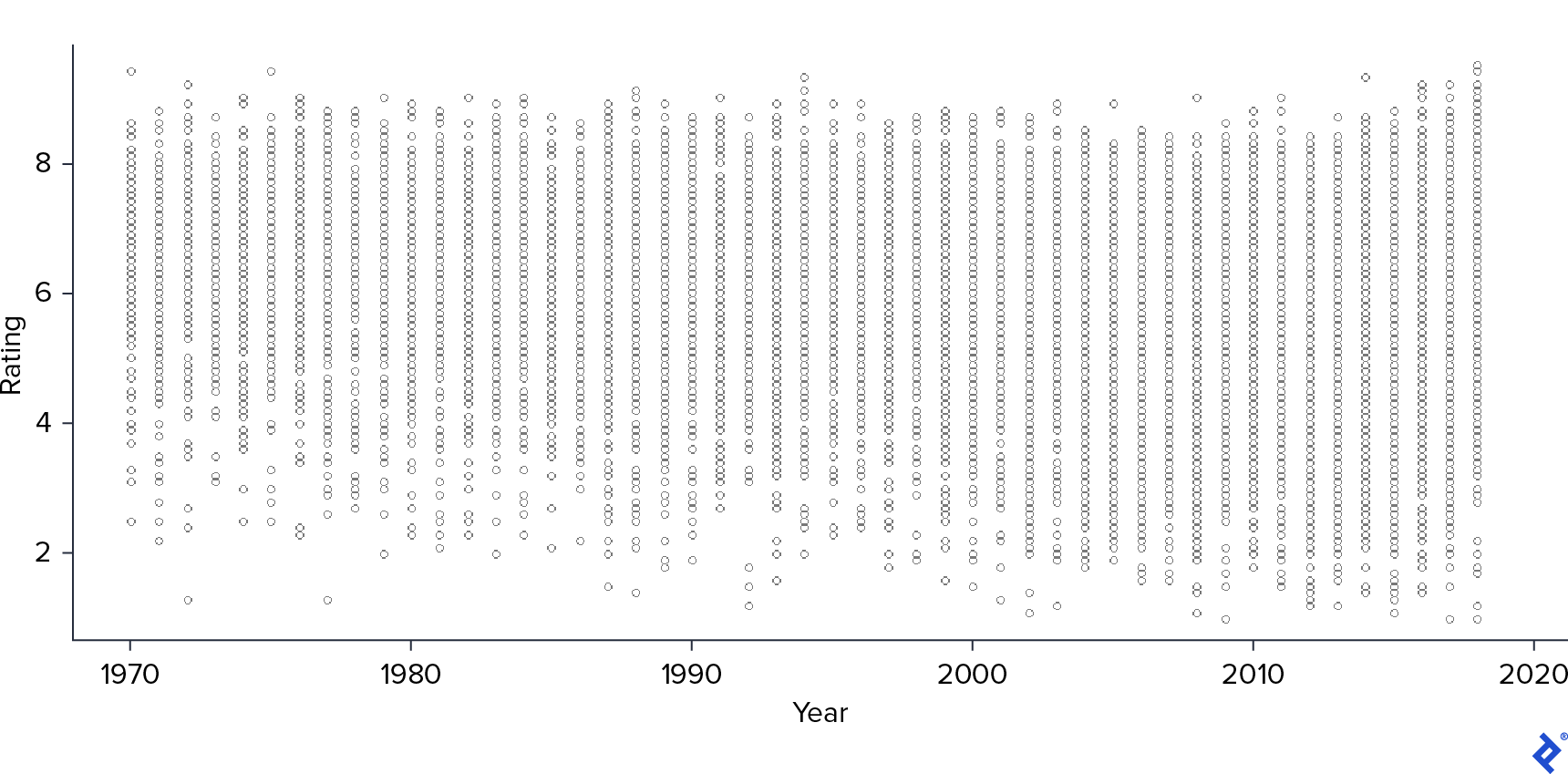
As we saw previously, Year 似乎与。呈负相关 Rating: As the year increases, 评级差异也会增加, 在新电影中达到更多的负值.
接下来,我做了同样的图 Votes.
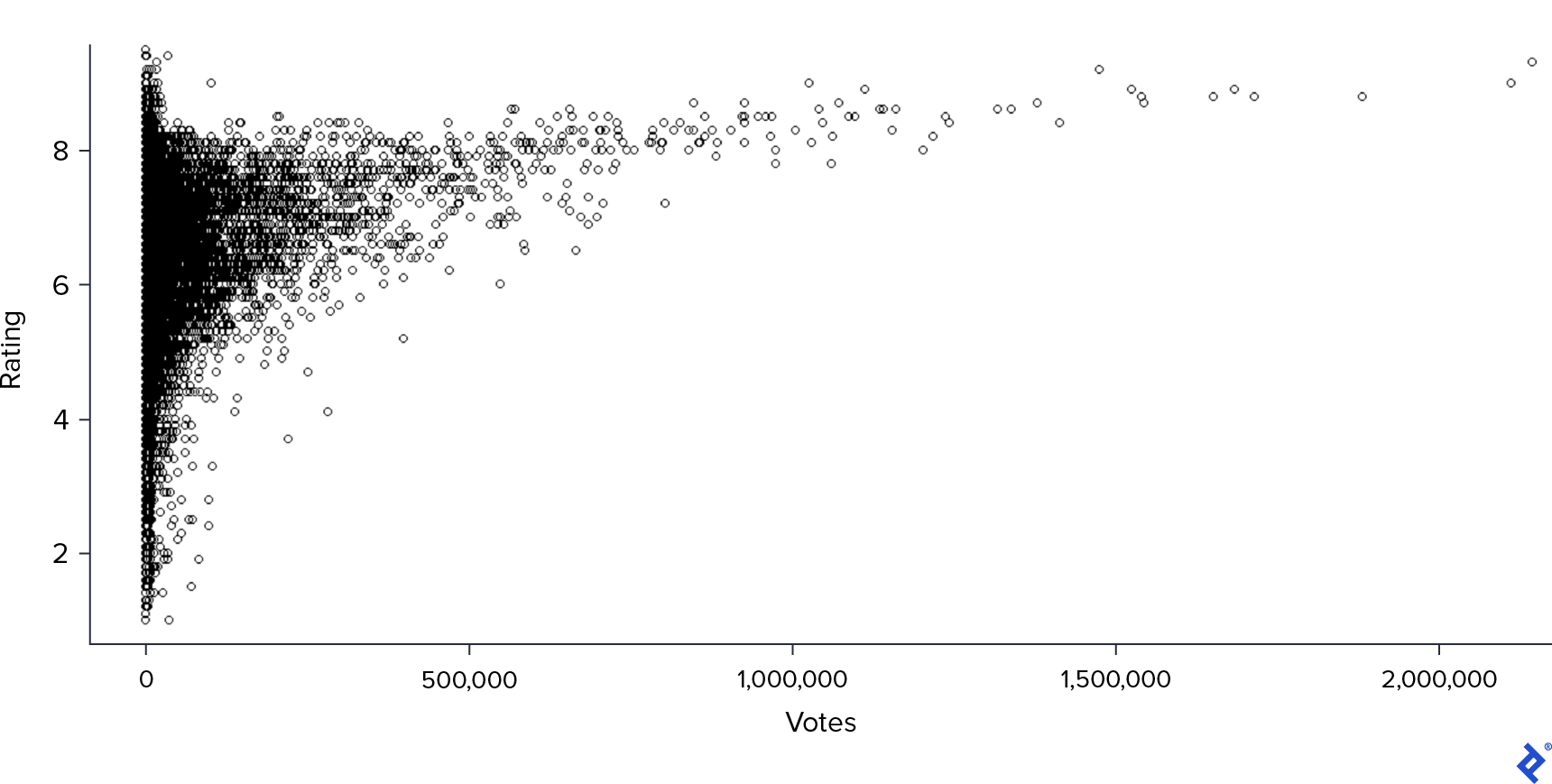
在这里,相关性更明显:得票越多,排名就越高. 然而,大多数电影都没有那么多的选票,在这种情况下, Rating had a bigger variance.
最后,我研究了与 Runtime.
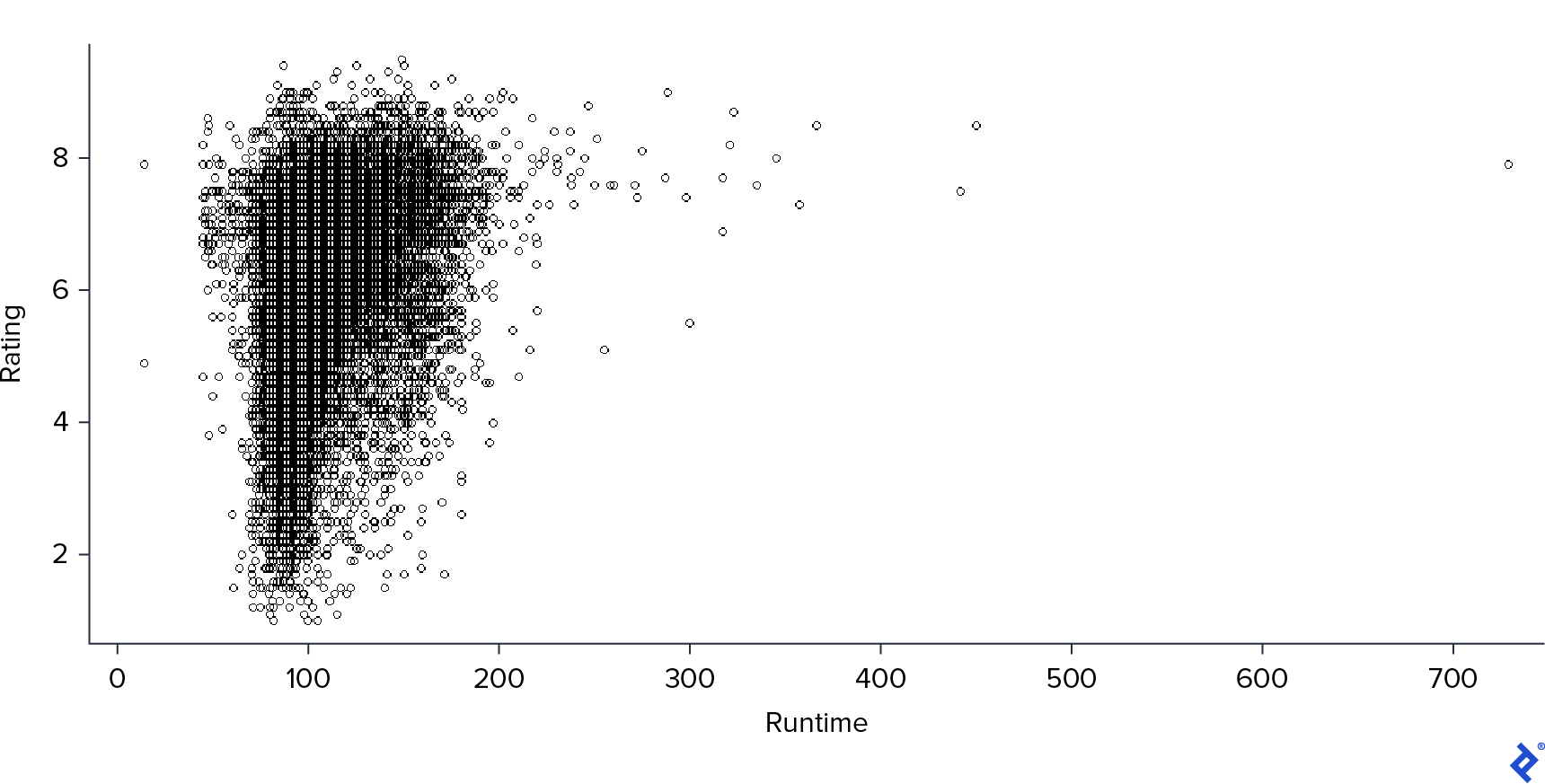
Again, 我们有一个类似的模式,但更强:更高的运行时间意味着更高的评级, 但是很少有高运行时的情况.
After all this analysis, 我对我正在处理的数据有了更好的了解, 所以我决定测试一些模型来预测基于这些字段的评分. 我的想法是我最好的模型预测和真实的 Rating 是否会消除共同特征的影响,并反映出使一部电影比其他电影更好的特定特征.
我从最简单的线性模型开始. 为了评估哪个模型表现更好,我观察了均方根(RMSE) and mean absolute (MAE) errors. 它们是完成这类任务的标准措施. 此外,它们与预测变量在同一尺度上,因此它们易于解释.
在第一个模型中,RMSE为1.03, and MAE 0.78. 但线性模型假设误差无关,中值为零,方差为常数. 如果这是正确的,“残差vs. 预测值的图形应该看起来像没有结构的云. 所以我决定用图表来证实这一点.
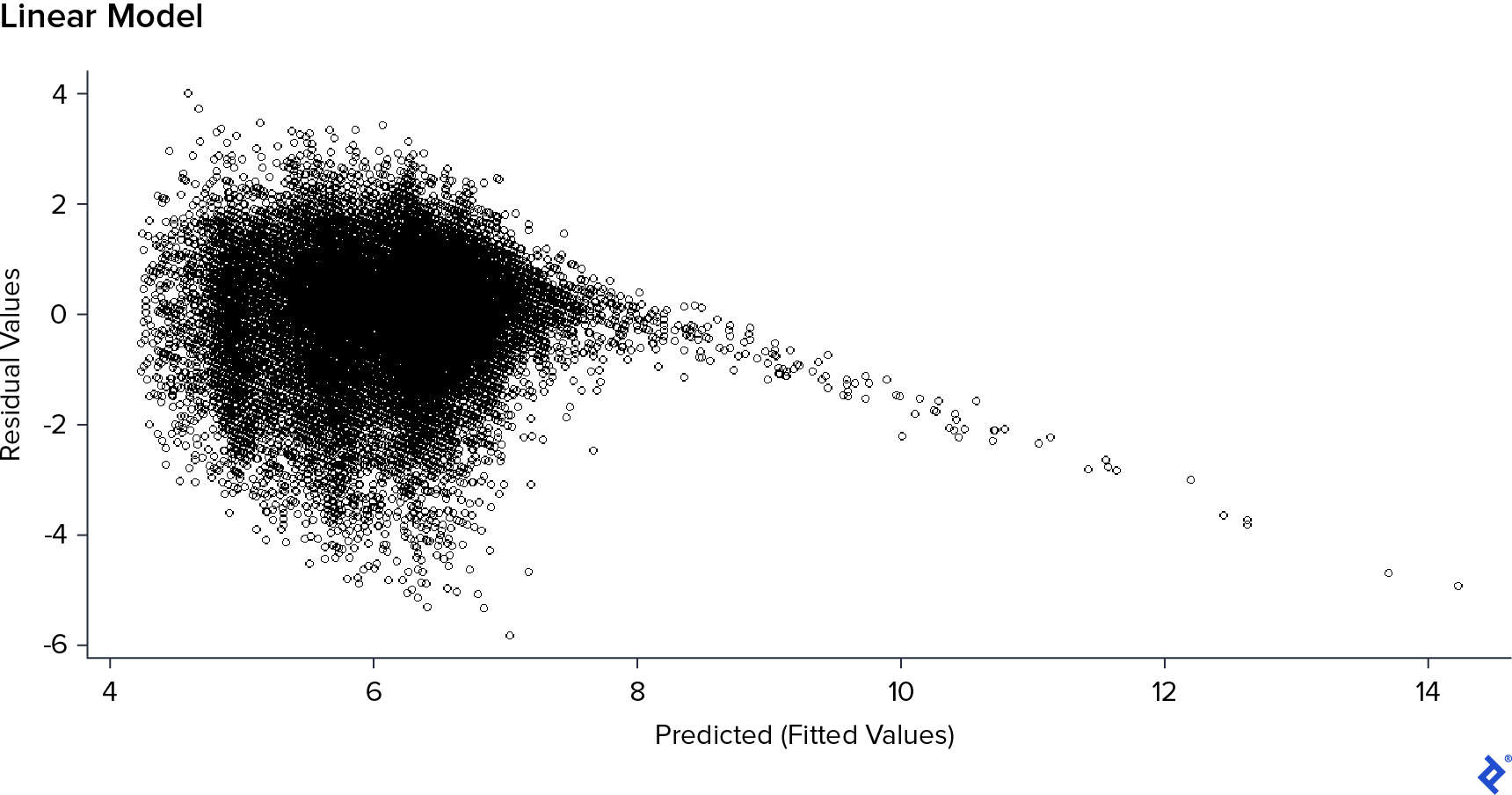
我可以在预测值中看到7, 它的形状是非结构化的, but after this value, 它有一个清晰的线性下降形状. Consequently, 模型的假设是错误的, and also, 我有一个“溢出”的预测值,因为在现实中, Rating can’t be more than 10.
在前面的IMDb数据分析中,用了较高的量 Votes, the Rating improved; however, this happened in a few cases and for a huge amount of votes. 这可能会导致模型扭曲并产生这种情况 Rating overflow. 为了验证这一点,我评估了在相同的模型下会发生什么,去掉 Votes field.
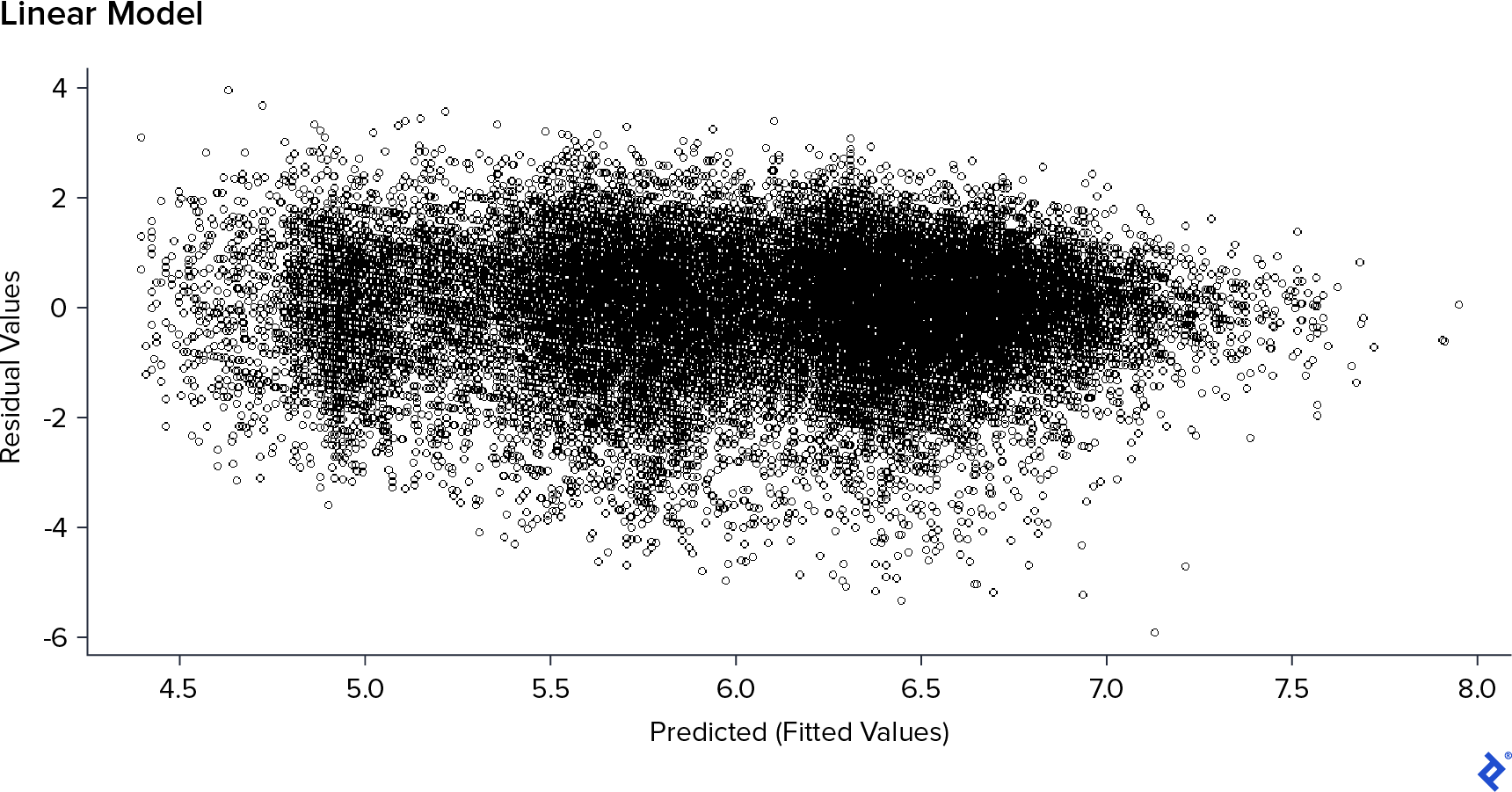
This was much better! 它具有更清晰、非结构化的形状,没有溢出预测值. The Votes 现场也取决于评论家的活动,而不是电影的一个特点, 所以我决定放弃这个领域. 删除后的误差为1.06 on RMSE and 0.81在mae上,稍微差一点, but not so much, 我更希望有更好的假设和特征选择,而不是在训练集上有更好的表现.
接下来我尝试了不同的模型来分析哪个表现更好. 对于每个模型,我使用 random search 技术优化超参数值和5倍 cross-validation to prevent model bias. 得到的估计误差如下表所示:
| Model | RMSE | MAE |
|---|---|---|
| Neural Network | 1.044596 | 0.795699 |
| Boosting | 1.046639 | 0.7971921 |
| Inference Tree | 1.05704 | 0.8054783 |
| GAM | 1.0615108 | 0.8119555 |
| Linear Model | 1.066539 | 0.8152524 |
| Penalized Linear Reg | 1.066607 | 0.8153331 |
| KNN | 1.066714 | 0.8123369 |
| Bayesian Ridge | 1.068995 | 0.8148692 |
| SVM | 1.073491 | 0.8092725 |
正如您所看到的,所有模型的表现都相似,因此我使用其中的一些模型来分析更多的数据. 我想知道每个领域对评分的影响. 最简单的方法是观察线性模型的参数. 但为了避免之前对它们的扭曲, 我缩放了数据,然后重新训练了线性模型. 重量如图所示.
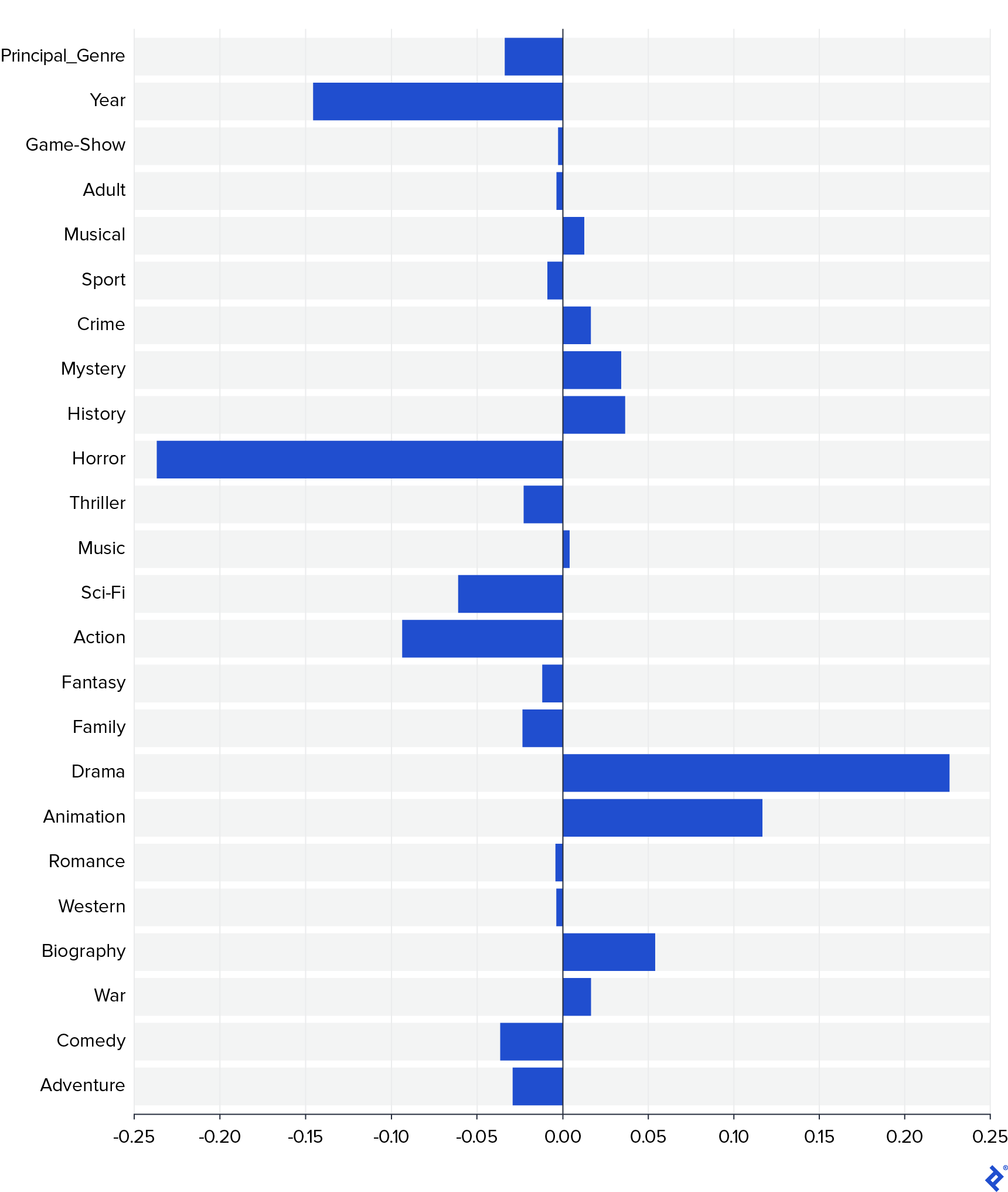
在这张图中,很明显两个最重要的变量是 Horror and Drama,其中第一个对评级有负面影响,第二个对评级有积极影响. 还有其他一些领域也会产生积极的影响 Animation and Biography—while Action, Sci-Fi, and Year impact negatively. Moreover, Principal_Genre 是否有相当大的影响, 所以一部电影有哪些类型比哪一个是主要类型更重要.
用广义加性模型(GAM), 我还可以看到对连续变量的更详细的影响, 在这种情况下,哪个是 Year.
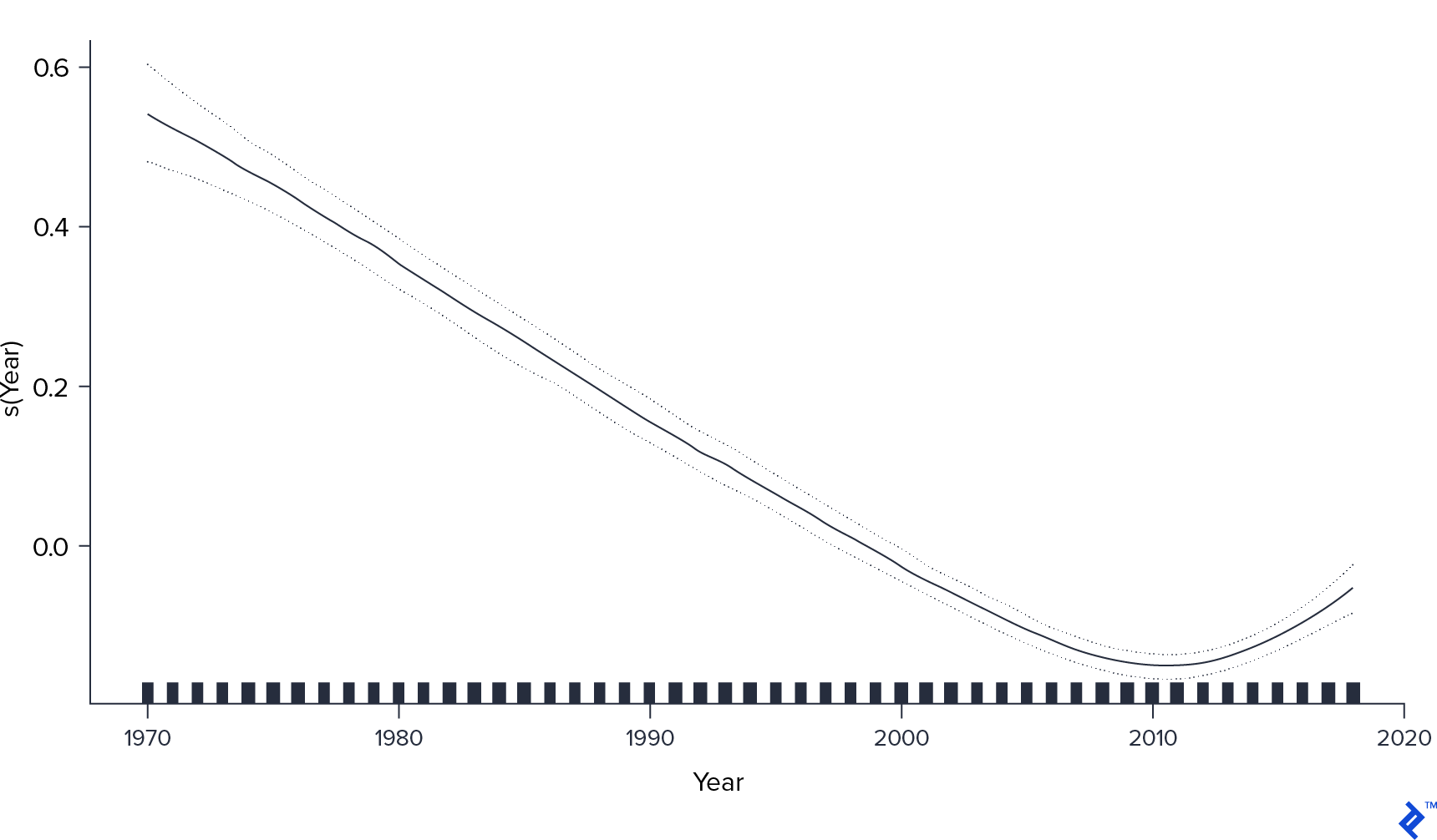
这里,我们有一些更有趣的东西. 虽然对于最近上映的电影,评分确实会降低,但这种影响并不是恒定的. 它在2010年达到最低值,然后似乎“复苏”.“在那一年之后,电影制作中发生了什么,导致了这种变化,这将是一件有趣的事情.
The best model was neural networks,其RMSE和MAE最低,但正如你所看到的,没有一个模型达到完美的性能. 但就我的目标而言,这并不是坏消息. 现有的信息让我对性能有了一定的估计,但这还不够. 还有一些我无法从IMDb中获取的信息 Rating 与预期分数的差异基于 Genre, Runtime, and Year. 它可能是演员表演、电影剧本、摄影或许多其他东西.
从我的角度来看,在选择看什么节目时,这些其他特征才是真正重要的. 我不在乎一部电影是剧情片、动作片还是科幻片. 我想要一些特别的东西, 能让我玩得开心的东西, 让我学到了一些东西, 让我反思现实, or just entertains me.
So I created a new, 通过采用IMDb评级并减去最佳模型的预测评级来改进评级. 通过这样做,我正在消除的影响 Genre, Runtime, and Year 保留这些未知的信息对我来说更重要.
现在让我们看看哪10部电影是我的新评级和. IMDb的真实评分:
IMDb
| Title | Genre | IMDb Rating | Refined Rating |
|---|---|---|---|
| Ko to tamo peva | Adventure,Comedy,Drama | 8.9 | 1.90 |
| Dipu Number 2 | Adventure,Family | 8.9 | 3.14 |
| El señor de los anillos: El reverno del rey | Adventure,Drama,Fantasy | 8.9 | 2.67 |
| El señor de los anillos: La comunidad del anillo | Adventure,Drama,Fantasy | 8.8 | 2.55 |
| Anbe Sivam | Adventure,Comedy,Drama | 8.8 | 2.38 |
| Hababam Sinifi Tatilde | Adventure,Comedy,Drama | 8.7 | 1.66 |
| El señor de los anillos: Las dos torres | Adventure,Drama,Fantasy | 8.7 | 2.46 |
| Mudras Calling | 冒险、戏剧、浪漫 | 8.7 | 2.34 |
| Interestelar | Adventure,Drama,Sci-Fi | 8.6 | 2.83 |
| Volver al futuro | Adventure,Comedy,Sci-Fi | 8.5 | 2.32 |
Mine
| Title | Genre | IMDb Rating | Refined Rating |
|---|---|---|---|
| Dipu Number 2 | Adventure,Family | 8.9 | 3.14 |
| Interestelar | Adventure,Drama,Sci-Fi | 8.6 | 2.83 |
| El señor de los anillos: El reverno del rey | Adventure,Drama,Fantasy | 8.9 | 2.67 |
| El señor de los anillos: La comunidad del anillo | Adventure,Drama,Fantasy | 8.8 | 2.55 |
| Kolah ghermezi va pesar khale | Adventure,Comedy,Family | 8.1 | 2.49 |
| El señor de los anillos: Las dos torres | Adventure,Drama,Fantasy | 8.7 | 2.46 |
| Anbe Sivam | Adventure,Comedy,Drama | 8.8 | 2.38 |
| la mesa cuadrada的骑士 | 冒险、喜剧、幻想 | 8.2 | 2.35 |
| Mudras Calling | 冒险、戏剧、浪漫 | 8.7 | 2.34 |
| Volver al futuro | Adventure,Comedy,Sci-Fi | 8.5 | 2.32 |
正如你所看到的,领奖台并没有发生根本性的变化. 这是意料之中的,因为均方根误差并没有那么高,现在我们看到的是顶部. 让我们来看看排名最后的10位发生了什么:
IMDb
| Title | Genre | IMDb Rating | Refined Rating |
|---|---|---|---|
| Holnap történt -一个纳吉bulvárfilm | Comedy,Mystery | 1 | -4.86 |
| Cumali Ceber:真主保佑 | Comedy | 1 | -4.57 |
| Badang | Comedy,Fantasy | 1 | -4.74 |
| Yyyreek!!! Kosmiczna nominacja | Comedy | 1.1 | -4.52 |
| Proud American | Drama | 1.1 | -5.49 |
| 棕大衣:独立战争 | Action,Sci-Fi,War | 1.1 | -3.71 |
| The Weekend It Lives | Comedy,Horror,Mystery | 1.2 | -4.53 |
| Bolívar: el héroe | Animation,Biography | 1.2 | -5.34 |
| Rise of the Black Bat | Action,Sci-Fi | 1.2 | -3.65 |
| Hatsukoi | Drama | 1.2 | -5.38 |
Mine
| Title | Genre | IMDb Rating | Refined Rating |
|---|---|---|---|
| Proud American | Drama | 1.1 | -5.49 |
| 圣诞老人和冰淇淋兔 | Family,Fantasy | 1.3 | -5.42 |
| Hatsukoi | Drama | 1.2 | -5.38 |
| Reis | Biography,Drama | 1.5 | -5.35 |
| Bolívar: el héroe | Animation,Biography | 1.2 | -5.34 |
| Hanum & Rangga: Faith & The City | Drama,Romance | 1.2 | -5.28 |
| After Last Season | Animation,Drama,Sci-Fi | 1.7 | -5.27 |
| Barschel - Mord in Genf | Drama | 1.6 | -5.23 |
| Rasshu raifu | Drama | 1.5 | -5.08 |
| Kamifûsen | Drama | 1.5 | -5.08 |
这里也发生了同样的事情, 但现在我们可以看到,在精炼版中出现的电视剧比在IMDb中出现的多, 这说明一些电视剧可能仅仅因为是电视剧而排名过高.
也许最有趣的领奖台是IMDb评分系统和我的评分之间差距最大的10部电影. 这些电影是那些在未知特征上有更多重量的电影,使电影比已知特征更好(或更差).
| Title | IMDb Rating | Refined Rating | Difference |
|---|---|---|---|
| Kanashimi no beradonna | 7.4 | -0.71 | 8.11 |
| Jesucristo Superstar | 7.4 | -0.69 | 8.09 |
| Pink Floyd The Wall | 8.1 | 0.03 | 8.06 |
| Tenshi no tamago | 7.6 | -0.42 | 8.02 |
| Jibon Theke Neya | 9.4 | 1.52 | 7.87 |
| El baile | 7.8 | 0.00 | 7.80 |
| 圣诞老人和三只熊 | 7.1 | -0.70 | 7.80 |
| 斯克鲁奇的历史 | 7.5 | -0.24 | 7.74 |
| Piel de asno | 7 | -0.74 | 7.74 |
| 1776 | 7.6 | -0.11 | 7.71 |
如果我是一个电影导演,必须制作一部新电影, 在做了所有这些IMDb数据分析之后, 我可以有一个更好的想法,什么样的电影做有一个更好的IMDb排名. 例如,这将是一部长动画传记剧,将是一部老电影的翻拍, Amadeus. 这可能会保证一个好的IMDb排名,但我不确定利润…
你怎么看在这个新标准中排名靠前的电影? Do you like them? 还是你更喜欢原版的? 请在下面的评论中告诉我!
IMDb (Internet Movie Database)是一个与视听内容相关的在线信息数据库.
IMDb评级系统是一种根据网络用户投票产生的分数对视听内容进行排序的方式.
IMDb的主要数据是关于电影的:它们存储标题, year, gross, duration, genre, 还有其他共同特征.
IMDb的目标是成为最大、最主要的视听内容百科全书.
Located in 布宜诺斯艾利斯城,阿根廷布宜诺斯艾利斯
Member since November 6, 2019
Juan(计算机科学硕士)是一名数据科学/人工智能博士生. 作为一名高级web开发人员,他的主要专长包括R、Python和PHP.
 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.世界级的文章,每周发一次.
世界级的文章,每周发一次.
Join the Toptal® community.
